References
[6] Hongsuk Choi, Gyeongsik Moon, Ju Yong Chang, and Kyoung Mu Lee. Beyond static features for temporally consistent 3D human pose and shape from a video. CVPR, 2021.
[8] Carl Doersch and Andrew Zisserman. Sim2real transfer learning for 3D human pose estimation: Motion to the rescue. NeurIPS, 2019.
[16] Catalin Ionescu, Dragos Papava, Vlad Olaru, and Cristian Sminchisescu. Human3.6M: Large scale datasets and predictive methods for 3D human sensing in natural environments. IEEE TPAMI, 36(7):1325–1339, 2014.
[17] Angjoo Kanazawa, Michael J. Black, David W. Jacobs, and Jitendra Malik. End-to-end recovery of human shape and pose. CVPR, 2018.
[18] Angjoo Kanazawa, Jason Y. Zhang, Panna Felsen, and Jitendra Malik. Learning 3D human dynamics from video. CVPR, 2019.
[20] Muhammed Kocabas, Nikos Athanasiou, and Michael J. Black. VIBE: Video inference for human body pose and shape estimation. CVPR, 2020.
[21] Nikos Kolotouros, G. Pavlakos, Michael J. Black, and Kostas Daniilidis. Learning to reconstruct 3D human pose and shape via model-fitting in the loop. ICCV, 2019.
[22] Nikos Kolotouros, G. Pavlakos, and Kostas Daniilidis. Convolutional mesh regression for single-image human shape reconstruction. CVPR, 2019.
[23] Matthew Loper, Naureen Mahmood, and Michael J. Black. MoSh: Motion and shape capture from sparse markers. ACM ToG, 33(6):220:1–220:13, 2014.
[25] Zhengyi Luo, S. Alireza Golestaneh, and Kris M. Kitani. 3D human motion estimation via motion compression and refinement. ACCV, 2020.
[27] Dushyant Mehta, Helge Rhodin, Dan Casas, Pascal Fua, Oleksandr Sotnychenko, Weipeng Xu, and Christian Theobalt. Monocular 3D human pose estimation in the wild using improved CNN supervision. 3DV, 2017.
[28] Gyeongsik Moon and Kyoung Mu Lee. I2L-MeshNet: Image-to-lixel prediction network for accurate 3D human pose and mesh estimation from a single RGB image. ECCV, 2020.
[34] Yu Sun, Yun Ye, Wu Liu, Wenpeng Gao, Yili Fu, and Tao Mei. Human mesh recovery from monocular images via a skeleton-disentangled representation. ICCV, 2019.
[37] Timo von Marcard, Roberto Henschel, Michael J. Black, Bodo Rosenhahn, and Gerard Pons-Moll. Recovering accurate 3D human pose in the wild using IMUs and a moving camera. ECCV, 2018.
[38] Xiaolong Wang, Ross B. Girshick, Abhinav Gupta, and Kaiming He. Non-local neural networks. CVPR, 2018.
[41] Hongwen Zhang, Yating Tian, Xinchi Zhou, Wanli Ouyang, Yebin Liu, Limin Wang, and Zhenan Sun. PyMAF: 3D human pose and shape regression with pyramidal mesh alignment feedback loop. ICCV, 2021.
|
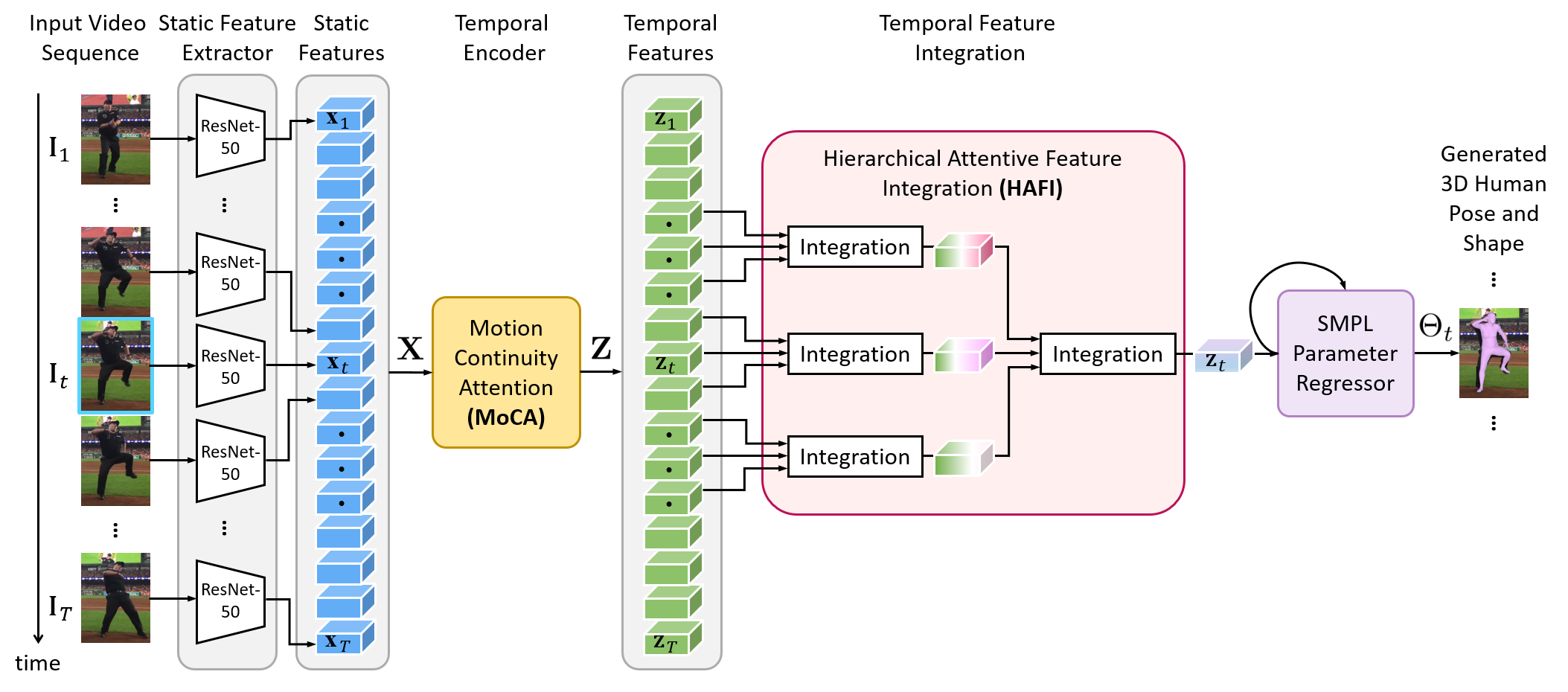 Overview of our motion pose and shape network (MPS-Net). MPS-Net estimates pose, shape, and camera parameters Θ in the video sequence based on the static feature extractor, temporal encoder, temporal feature integration, and SMPL parameter regressor to generate 3D human pose and shape.
Overview of our motion pose and shape network (MPS-Net). MPS-Net estimates pose, shape, and camera parameters Θ in the video sequence based on the static feature extractor, temporal encoder, temporal feature integration, and SMPL parameter regressor to generate 3D human pose and shape.